
Designing a Usage-Based Meter in 3 Weeks Instead of 3 Quarters
Using AI assistants to compress usage-based meter design from quarters to weeks without giving up the operator judgment that keeps meters honest.
The AI Usage-Based Pricing Meter Designer: How Pricing Leaders Use Claude or GPT-5 to Design Meters in Weeks, Not Quarters
If your last meter change took a quarter, produced one candidate, and landed without a rollback plan, you are not doing meter design. You are doing meter defense. The AI tools available now compress the loop by roughly an order of magnitude, but only if the operator stays in charge of the judgment the model cannot make.
TL;DR
- Meter design is the hardest part of usage-based pricing because the meter is the sentence customers read before the number, and changing it forces buyers to rethink the whole shape of the deal.
- AI assistants like Claude and GPT-5 compress candidate generation, invoice simulation, and readability drafting from quarters into weeks. They do not compress the judgment call.
- A meter-candidate brief written before the prompt is the single most consequential artifact in the whole sprint. Write it first, in plain language, with the unit economics and the rollback appetite stated.
- Three to five candidates is the right number. One expected winner, one sales-preferred, one finance-preferred, one deliberate outlier. The outlier keeps the comparison honest.
- Instrument the rollback plan before the flip. Teams that do this ship more meters and argue less after launch.
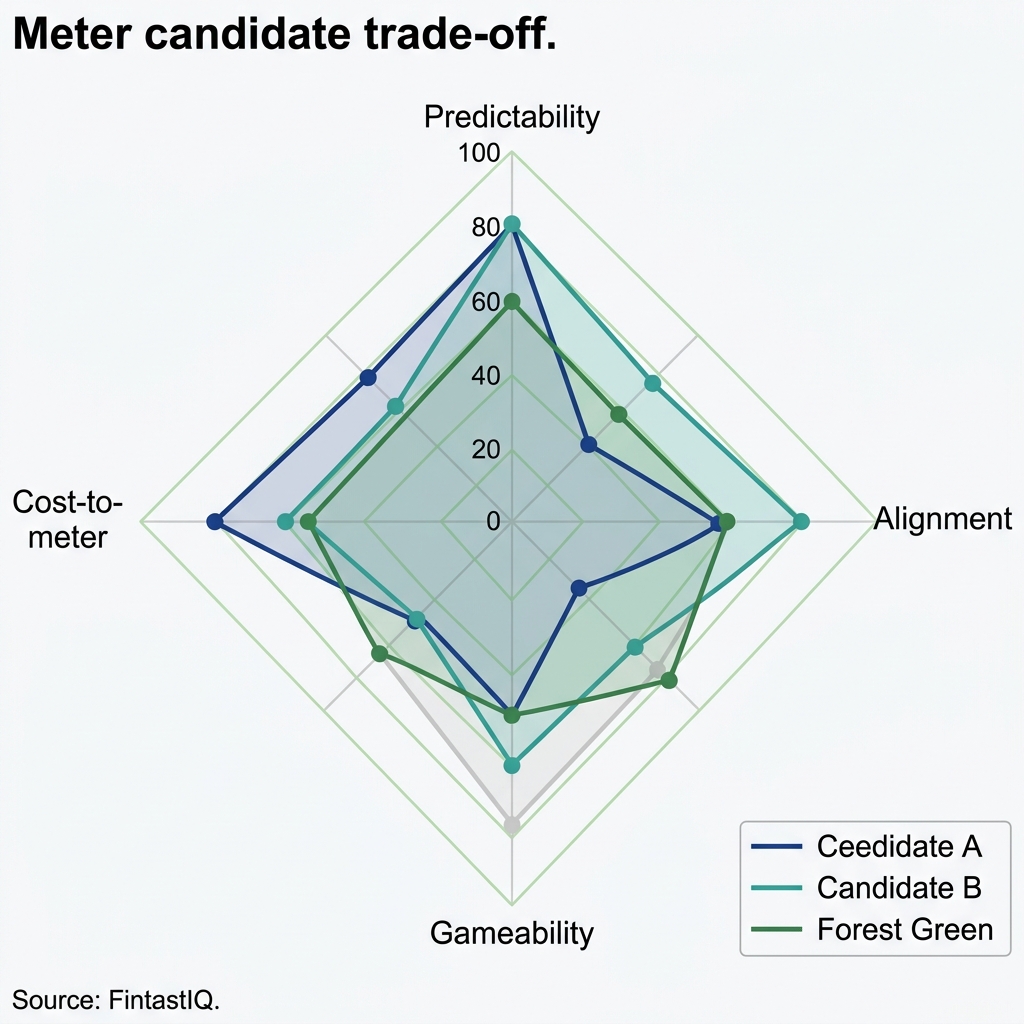 Exhibit: Meter candidate trade-off radar
Exhibit: Meter candidate trade-off radar
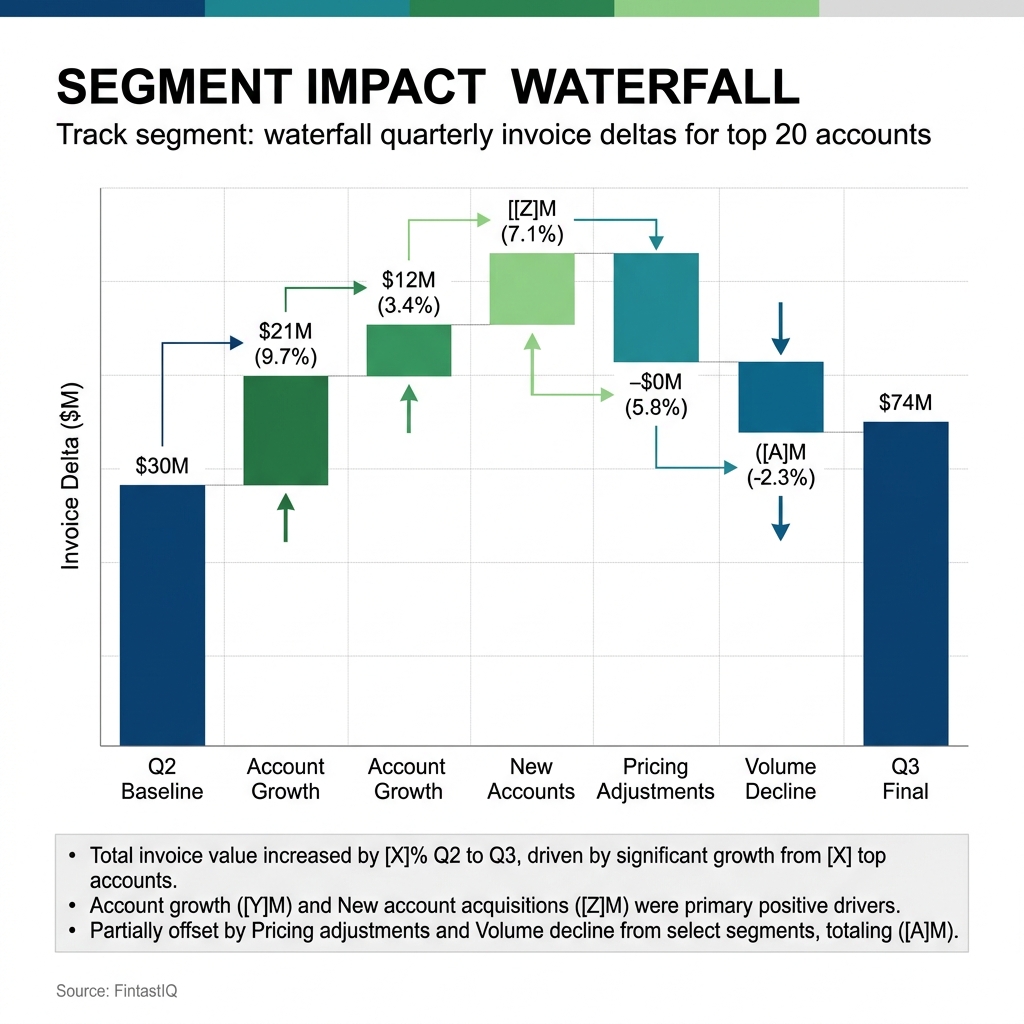 Exhibit: Segment impact waterfall
Exhibit: Segment impact waterfall
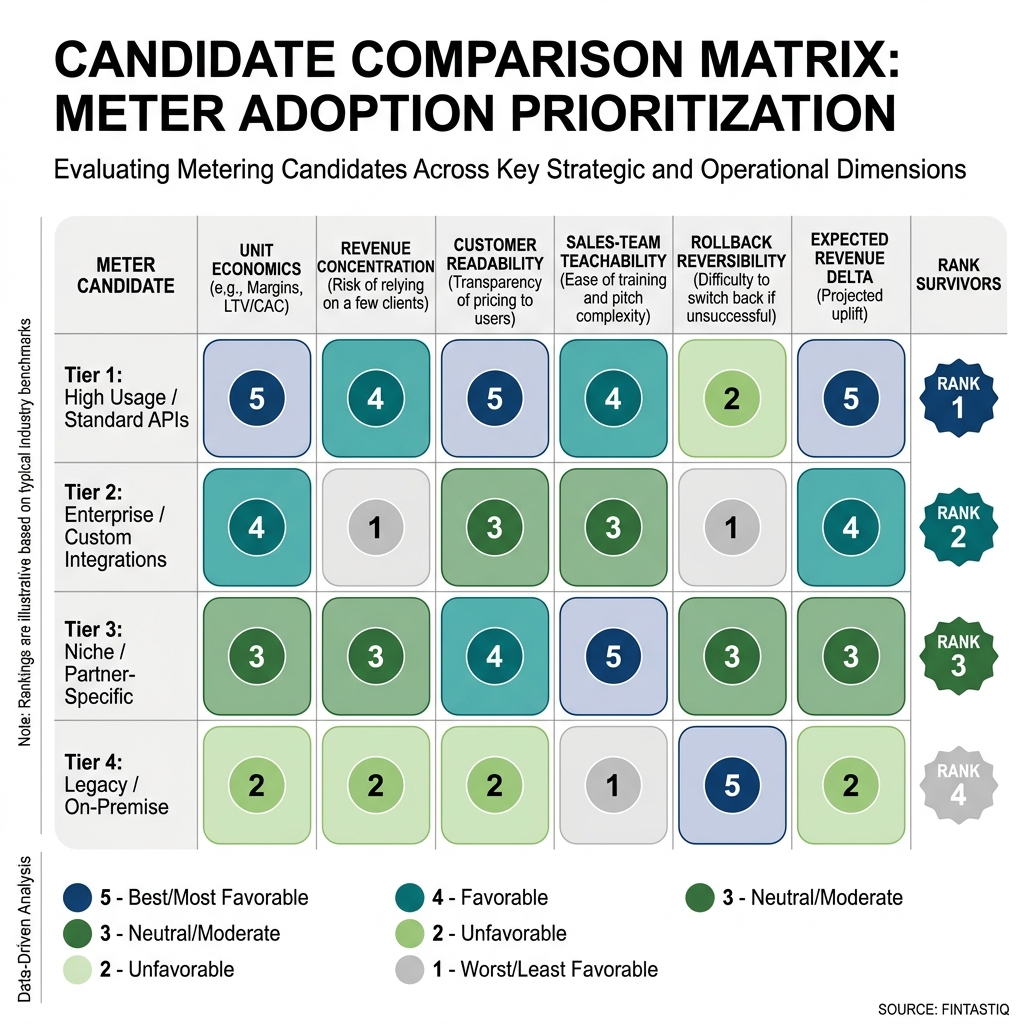 Exhibit: Meter-candidate comparison matrix
Exhibit: Meter-candidate comparison matrix
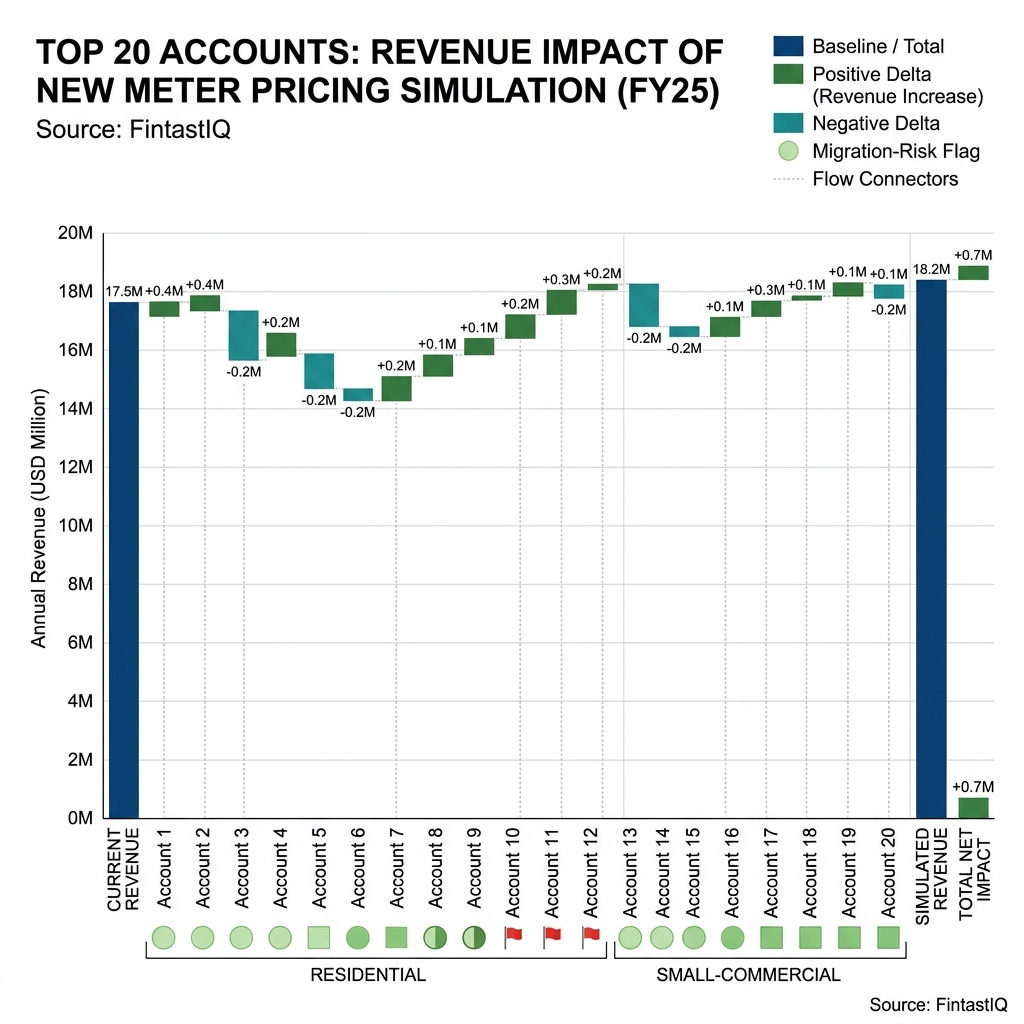 Exhibit: Simulated-invoice impact waterfall
Exhibit: Simulated-invoice impact waterfall
The core problem, with Delta Current as the anchor
Delta Current is a 95-person energy-storage marketplace running into 3,400 residential homes and 420 small-commercial sites across California, Texas, and the Northeast. Hardware suppliers ship residential and small-commercial battery systems priced between $4,000 and $22,000. Delta Current runs the aggregator platform on top, routing stored power into wholesale grid-arbitrage windows and charging customers a recurring fee in the $0.04 to $0.11 per kilowatt-hour routed range. Annual revenue sits at $64 million, split roughly 34 percent hardware take and 66 percent recurring meter revenue. Gideon is the CPO. He owns the meter.
Two years ago Delta Current had four live meter candidates in production at once. Some customers were billed on kilowatt-hours routed. Some on a percentage of arbitrage revenue captured. Some on a flat monthly fee per installed kilowatt of capacity. Some on a tiered subscription with a routed-energy cap. None of these were wrong on paper. Together they were a mess. The sales team could not quote a new site without a call to finance. The renewals team could not explain why a neighbor on the same street paid a different amount. Gideon retired two meters, merged the survivors, and scaled one meter to 87 percent of recurring revenue. The redesign cycle that used to take his team eight weeks now takes three, and the last meter swap lifted recurring revenue 22 percent against the pre-swap cohort.
What changed was not the meter itself. What changed was the loop around the meter. Gideon and one data scientist now run twelve AI-assisted meter simulations per week during an active sprint. Over the past year they have iterated on fourteen meter candidates across the portfolio, compared to roughly forty historical iterations over the prior four years. The compression is real. The selection discipline is the part the tools do not supply.
Four-part framework
1. Write the meter-candidate brief before prompting the model
Before Gideon opens Claude or GPT-5, he writes a one-page brief. The brief names the product line, the current meter, the symptom that prompted the sprint, the unit economics floor below which no candidate survives, the readability constraint for the sales team, and the rollback appetite of the business. On the Delta Current residential line, the brief stated that any candidate had to defend gross margin above 41 percent at the median site, had to be explainable on a single page with one formula, and had to be reversible inside ninety days without manual billing repair.
The brief is the guardrail. Without it, the model will happily produce fifty elegant candidates, none of which respect the constraints the business cannot move. Pricing is a signal before it is a number, and the brief forces the team to state the signal they want to send before they look at any mechanics. Gideon keeps a template in Notion with nine prompts. The data scientist fills it in for every sprint. The brief is reviewed by the head of sales and the head of finance before a single simulation runs. This feels slow on day one. It pays back on day four when the team is not arguing about whether a candidate is allowed to exist.
The discipline also protects against what Gideon calls the demo effect. Models produce fluent prose. Fluent prose feels like a decision. A written brief keeps fluency from substituting for judgment.
2. Simulate three to five meter candidates against real invoice data
With the brief in hand, the team generates candidates and simulates each against the last twelve months of real invoice data. Not synthetic. Real. The simulation produces a per-customer delta, a per-cohort delta, a margin curve, and a concentration check that flags any candidate where more than 15 percent of revenue ends up on fewer than ten accounts.
Delta Current typically runs four candidates per sprint. One is the expected winner, usually a refinement of the current meter. One is what the sales team wants, often simpler and flatter. One is what finance wants, often more granular with tighter margin capture. One is a deliberate outlier, sometimes a meter borrowed from an adjacent category like logistics or telecom. The outlier exists to break the team out of the current frame. When the outlier wins the simulation, the team treats it as a signal that the framing was wrong, not a signal that the outlier is the answer.
The AI assistant does the heavy arithmetic. It rewrites invoices at scale, flags edge cases, and drafts the comparison matrix. Gideon and the data scientist do the interpretation. A candidate that lifts revenue 9 percent while shifting concentration onto twelve commercial accounts is not a winner. It is a risk transfer. The simulation surfaces that. The operator has to name it.
Packaging beats pricing in almost every one of these sprints. The winning candidate is rarely the cleverest formula. It is usually the one that lets the sales team bundle the hardware and the recurring fee into a story the buyer already believes.
3. Test for customer readability and sales-team teachability
A meter that the customer cannot read is a meter that the customer discounts in their head. A meter that the sales team cannot teach is a meter the sales team quietly stops quoting. Both failure modes are invisible in simulation and obvious in the field.
Delta Current runs two readability tests on every finalist candidate. The first is the sixty-second test. A new sales hire, ideally under thirty days tenure, explains the meter to three prospects. The prospects repeat it back in their own words. If the repeat-back is accurate for at least two of the three, the meter passes. If not, the candidate is either rewritten or dropped. The second test is the teach-back. A senior account executive teaches the meter to a peer without a deck, only a whiteboard. If the peer cannot quote a site using only what they heard, the candidate has a teachability problem.
Confusion is the enemy of willingness to pay. Gideon has watched three technically superior candidates lose to a slightly worse meter that the buyer could model in their head. The readability test is cheap, roughly a day of calendar time and a handful of recordings, and it is the most common shortcut teams take when they are under deadline pressure. The shortcut is always visible twelve months later in the renewal data.
AI assistants help by drafting the customer-facing explanation in five voices and surfacing ambiguous phrases. The phrase that ships belongs to the humans who will defend it on a Tuesday afternoon sales call.
4. Instrument the rollback plan before you flip the meter
The rollback plan is not a backup. It is a precondition. Before Delta Current flips a new meter into production, the team writes down the quantitative trigger that would force a reversion, the single decision owner, the contractual mechanism, the billing-systems path back, and the customer-facing script. The trigger is specific. On the most recent flip it was: if net revenue retention on the migrated cohort drops below 94 percent at day sixty, or if the dispute rate on the first invoice cycle exceeds 6 percent, Gideon reverts.
Naming the trigger before launch does two things. It forces the team to be honest about what failure looks like, which usually reveals a weak spot in the candidate that simulation missed. And it lets the team ship faster because the downside is bounded. The best operators compete on discipline, not instinct, and the rollback plan is the cheapest discipline artifact in the whole sprint.
Teams without a rollback plan ship fewer meters and let failed ones linger, because reverting feels like admitting a mistake. Teams with one treat reversion as a normal operating mode. Delta Current has reverted two meters in three years. Neither produced a churn event, because the customers had been told the trigger existed.
Three failure modes to avoid
Model-worship. Letting the AI pick the meter. The model is fluent, and fluency reads as confidence. A meter that wins on the simulation matrix but cannot be taught to a junior AE in sixty seconds will lose in the field. The operator picks the meter. The model widens the option set.
Simulation-without-rollback. Running beautiful simulations, picking a candidate, shipping it, and then discovering there is no clean path back. This is the failure mode that turns a two-week reversion into a two-quarter cleanup. Instrument rollback on day one of the sprint, not day one after launch.
Meter-proliferation. Saying yes to every new meter a PM or a customer requests. The portfolio grows, the sales team slows, renewals get awkward, and nobody can hold the pricing in their head. Pricing maturity is measured by what you stop doing. Audit the meter portfolio every two quarters. Retire anything under a materiality threshold. Merge the overlapping meters. Then, and only then, consider adding.
30-60-90 sprint
Days 0 to 30. Write the meter-candidate brief. Pull twelve months of invoice data into a clean table. Generate three to five candidates with the AI assistant against the brief. Run the first-pass simulation. Kill anything that breaches the unit economics floor. Shortlist two finalists.
Days 31 to 60. Run the sixty-second test and the teach-back on both finalists. Draft the customer-facing explanation in multiple voices. Pick the one the head of sales can defend. Write the rollback plan, including the numeric trigger, the decision owner, the contractual mechanism, and the customer script. Walk the plan through finance and legal.
Days 61 to 90. Flip the meter for a migration cohort of roughly 10 percent of affected accounts. Monitor the trigger metrics weekly. If triggers hold, expand to 50 percent at day seventy-five and to full rollout at day ninety. If a trigger fires, revert inside the named window. Document what the simulation missed and update the template.
What we do not share publicly
The meter-candidate brief template is internal. The simulation prompts are internal. The rollback-trigger thresholds are internal because they encode risk appetite specific to the operator and the board. What we publish is the shape of the method. The numeric edges stay with the team that owns the P&L. A threshold that works at Delta Current at 66 percent recurring mix will be wrong for a hardware-heavy operator at 15 percent recurring mix, and publishing the number would cause more damage than value.
FAQ
Why is meter design the hardest part of usage-based pricing? The meter is the sentence the customer reads before the number. Change the price and customers compare. Change the meter and customers rethink the shape of the deal. A good meter tracks something the buyer believes creates value, the seller can measure cheaply, and the sales team can explain in one breath. Getting all three is rare.
Should the AI pick the meter for us? No. The model is faster at generating candidates, simulating against invoice data, and drafting customer-facing explanations. It is not faster at judging whether a meter fits the market or the sales motion. The signal choice belongs to the operator. Use the model to widen the option set and compress the math.
How many meter candidates should we simulate? Three to five. Fewer than three confirms a prior. More than five makes the comparison matrix unreadable. The right set is one expected winner, one sales-preferred, one finance-preferred, one deliberate outlier. When the outlier wins, the framing was usually wrong and the brief needs reopening.
How do we know a meter is readable enough? When a new sales hire can explain it in under sixty seconds and the buyer can repeat it back without the sheet. Confusion is the enemy of willingness to pay. The readability test costs a day of calendar time. Teams that skip it under deadline pressure rework the meter twelve months later.
What is a meter-design sprint versus a pricing review? A review asks whether the numbers are right. A sprint asks whether the unit of charging is right. Review runs quarterly against margin and win rate. Sprint runs when a new product line lands, a competitor reframes the category, or invoices start producing arguments. Running a review on a sprint cadence teaches buyers to wait you out.
How does this apply outside software? The problem is identical in marketplaces picking take rates, hardware-plus-consumables businesses deciding where margin sits, metered services where the unit of charging shapes behavior, and B2B2B royalty platforms where the meter determines who captures surplus. The framework assumes someone pays per something and the something is under debate.
What should we stop doing before adding a new meter? Audit the portfolio and retire anything below a materiality bar. Pricing maturity is measured by what you stop doing. Most teams drift to eight or nine units of charging because a PM or a customer asked. Retire the low-revenue meters first, merge the overlapping ones, then ask whether the new candidate still earns its place.
What does a rollback plan contain? A quantitative trigger defined before launch. A single decision owner. A contractual and systems mechanism that reverts without manual billing repair. A customer script that explains the reversion without admitting more than is true. Teams that instrument rollback ship more meters and argue less.
Run the free assessment or book a consultation to apply this framework to your specific situation.
Questions, answered
8 QuestionsWhy is meter design the hardest part of usage-based pricing to get right?
Because the meter is the sentence the customer reads before they see a number. Change the price and customers compare. Change the meter and customers have to rethink the whole shape of the relationship. A good meter tracks something the buyer already believes creates value, something the seller can measure cheaply, and something the sales team can explain in one breath. Getting all three at once is rare. Most teams only find out they failed after a renewal cycle, which is why shortening the design loop matters more than sharpening any single candidate.
Should an AI like Claude or GPT-5 pick the usage meter for a pricing team?
No. The AI is faster than any human at generating candidates, stress-testing them against invoice data, and drafting customer-facing explanations. It is not faster at judging whether a meter fits the market, the sales motion, or the way your board thinks about revenue quality. Pricing is a signal before it is a number. The signal choice belongs to the operator. Use the model to widen the candidate pool and compress the math. Keep the selection decision in the room with the people who own the P&L.
How many usage-based meter candidates should a pricing team simulate in a sprint?
Three to five. Fewer than three and you are confirming a prior. More than five and the comparison matrix becomes unreadable and the team starts picking on aesthetics rather than evidence. The goal is a set wide enough to include one candidate you expect to win, one candidate the sales team wants, one candidate finance wants, and one deliberate outlier. The outlier exists to keep the comparison honest. When the outlier wins, listen carefully. That is usually the moment the framing was wrong.
How do you know a usage-based meter is readable enough for buyers to accept?
A meter is readable when a new sales hire can explain it to a skeptical buyer in under sixty seconds and the buyer can repeat it back without the sheet. Confusion is the enemy of willingness to pay. If buyers need a spreadsheet to model their own bill, they discount the offer in their head to cover the uncertainty. The readability test is cheap to run with three real prospects and a recording. Most teams skip it because it feels unscientific. The teams that skip it also tend to rework the meter twelve months later.
What's the difference between a meter-design sprint and a quarterly pricing review?
A pricing review asks whether the numbers are right. A meter-design sprint asks whether the unit of charging is right. They are different muscles. A review happens every quarter against margin and win rate. A sprint happens when a new product line lands, when a competitor reframes the category, or when the existing meter is producing invoices the customer argues about. Running a sprint on a review cadence is wasteful. Running a review on a sprint cadence means you are changing the meter faster than buyers can learn it, and teaching them to wait you out.
Does usage-based meter design apply to marketplaces, hardware-plus-consumables, or B2B2B royalty platforms?
The meter-design problem is identical in marketplaces choosing between percentage take, flat listing fees, or success-based splits. It shows up in hardware-plus-consumables businesses deciding whether the margin sits in the device, the cartridge, or the service contract. It appears in metered services like energy, logistics, and data transport where the unit of charging shapes behavior. It surfaces in B2B2B royalty platforms where the meter determines who captures the surplus. The framework does not assume software. It assumes someone is paying per something and the definition of the something is under debate.
What should a pricing team stop doing before adding a new usage meter?
Audit the meters already in production and retire the ones that do not clear a materiality bar. Pricing maturity is measured by what you stop doing. Most teams add meters because a single customer asked, or because a PM wanted to monetize a feature, and the portfolio quietly grows to eight or nine units of charging that nobody can hold in their head. Retire the low-revenue meters first. Merge the overlapping ones. Then ask whether the new candidate still earns its place. Usually it does not, which is a useful finding.
What does a usage-based pricing rollback plan actually need to contain?
A rollback plan names the trigger, the decision owner, the reversal mechanism, and the customer communication. Trigger is the quantitative signal that the new meter is failing, defined before launch rather than after. Decision owner is one person, not a committee. Reversal mechanism is the contractual and systems path back to the prior meter without manual billing repair. Customer communication is the script that explains the reversion without admitting more than is true. Teams that instrument rollback ship more meters because they fear the downside less. Teams that do not, ship fewer and suffer more.
Using AI assistants to compress usage-based meter design from quarters to weeks without giving up the operator judgment that keeps meters honest.
How relevant and useful is this article for you?
About the Author(s)
 Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
References
- Madhavan Ramaswamy & Georg Tacke. Monetizing Innovation. Wiley, 2016
- Thomas Nagle & Georg Müller. The Strategy and Tactics of Pricing. Routledge, 2016
- Wes Bush. Product-Led Growth. Product-Led Institute, 2019
- Rafi Mohammed. The Good-Better-Best Approach to Pricing. Harvard Business Review, 2018
- OpenView Partners. SaaS Benchmarks Report. OpenView Partners, 2023