
From 41-Day Signal Lag to 3 Days: The Weekly CI Agent
Replacing ad hoc competitor tracking with an agentic weekly brief built in Claude or GPT-5, instrumented against time-to-signal, decisions influenced, and open rate.
The AI Competitive Intelligence Brief: How Marketing Leaders Build a Weekly CI Agent in Claude or GPT-5
Hook
Your last competitor pricing surprise reached your exec team 41 days after it went live. Your analyst spent six hours building a deck about it. Your CEO asked why you did not see it sooner. You did not see it sooner because your competitor tracker is a 47-page document nobody reads and a Slack channel that went quiet in Q2.
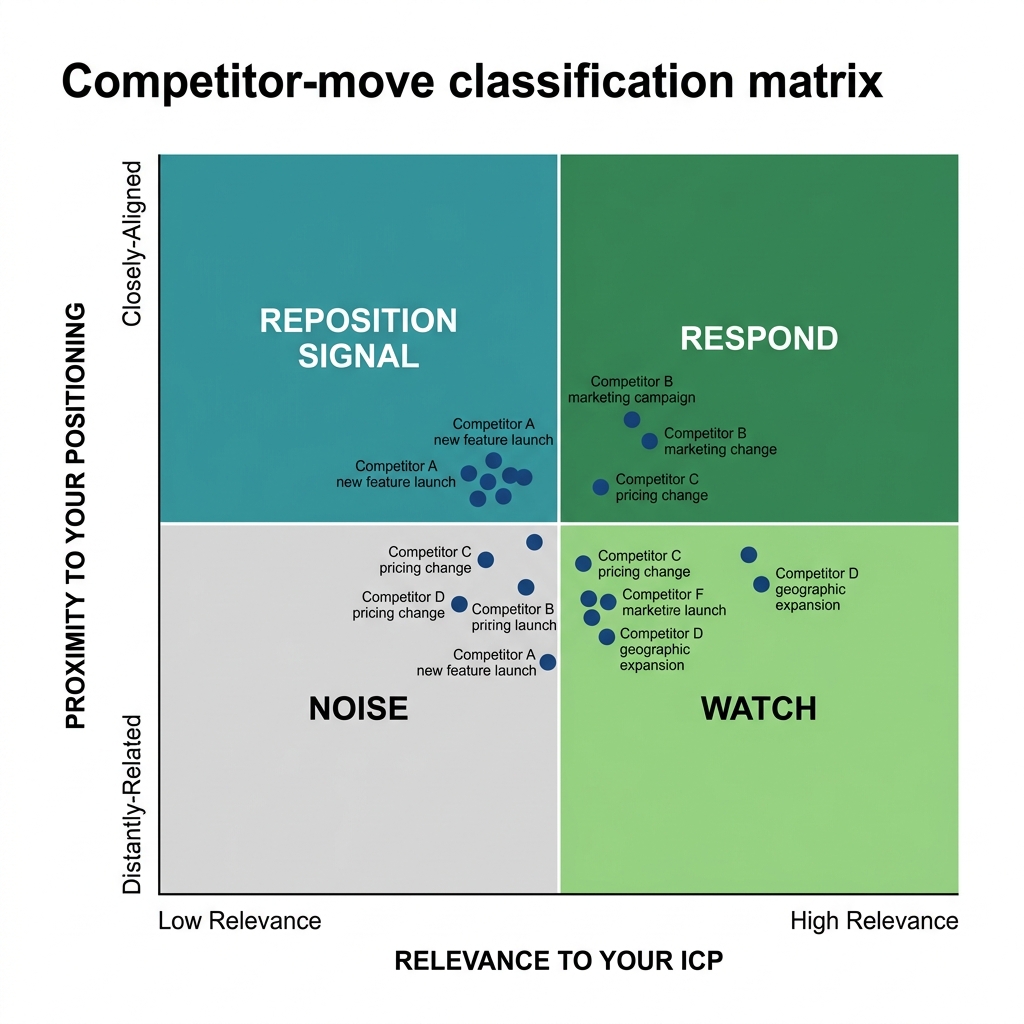 Exhibit: Competitor-move classification matrix
Exhibit: Competitor-move classification matrix
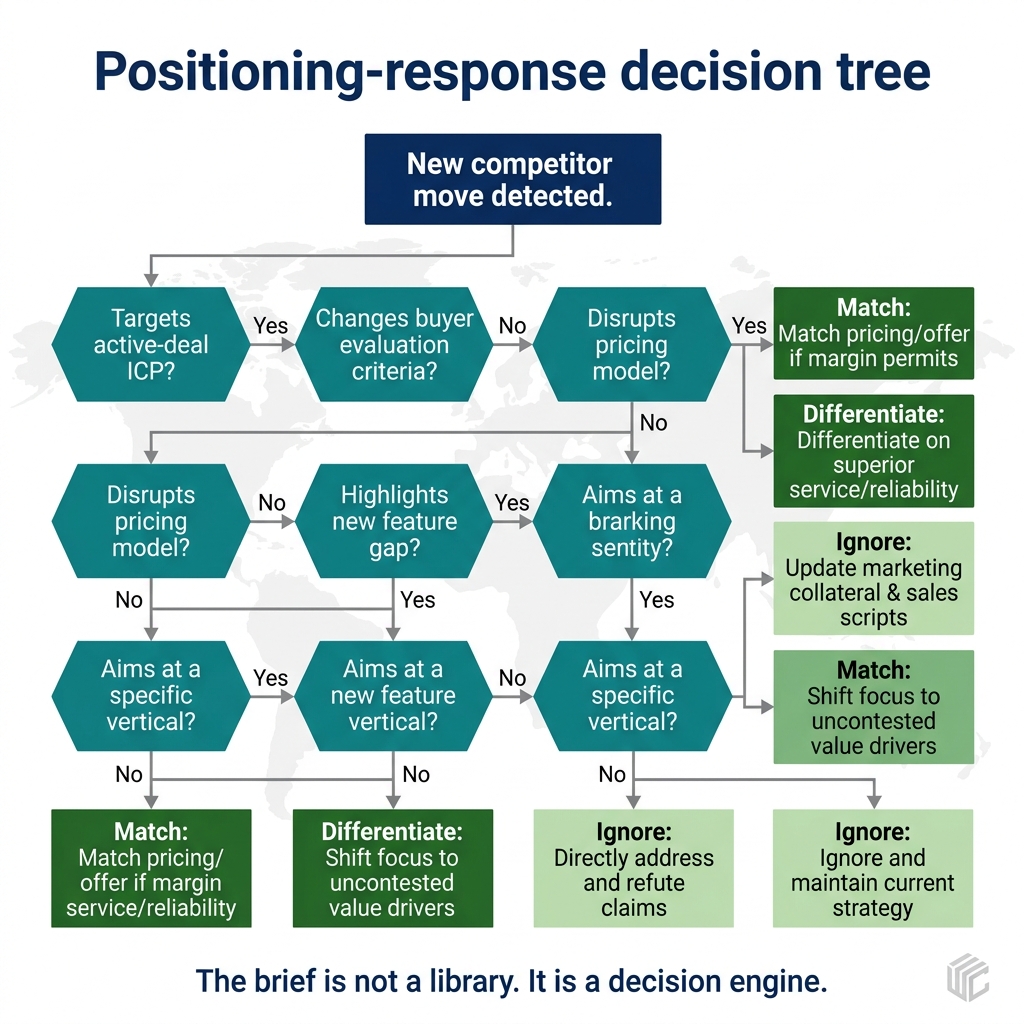 Exhibit: Positioning-response decision tree
Exhibit: Positioning-response decision tree
TL;DR
- Most B2B and consumer companies with $50M to $500M in revenue run competitor intelligence as an abandoned tracker document plus one stressed analyst. The result is a 30-to-60-day signal lag and commercial teams flying on instinct.
- A weekly agentic CI brief built on a frontier model, a lightweight crawler, a diff utility, and a living positioning document replaces 6 to 10 analyst hours per week and collapses time-to-signal from weeks to days.
- The asset is the prompt library, not the platform. Owning the classification logic is what turns signal into judgment and judgment into commercial decisions.
- Instrument three metrics from day one: open rate (target 70 percent), decisions influenced (pricing, positioning, roadmap moves that cite the brief), and time-to-signal (lag between a competitor move going live and the brief naming it).
- Pricing maturity is measured by what you stop doing. A well-tuned brief should classify most competitor pricing moves as noise, with documented reasons. Teams that respond to every move are reacting, not operating.
The core problem: competitor tracking is organizational theater
Most companies we meet run competitor intelligence as a performance of diligence rather than a source of decisions. There is a shared tracker document, usually started by a PMM two or three org charts ago. There is a Slack channel with four sales reps and a product marketer dropping links. There is a quarterly competitive deck that nobody updates between board meetings.
Take Ferrous Labs. 140 people, $48M ARR, an industrial-data analytics platform serving steel mills, foundries, and metal-recycling operators in North America and Central Europe. Irina, the CMO, inherited a 47-page competitor tracker document from her predecessor. She also inherited a team convinced they knew the competitive landscape cold. When a legacy incumbent dropped its starter tier from $299 to $199 per seat per month, Ferrous Labs caught it 41 days later, through a prospect who had accepted the other quote and called back to negotiate.
Ferrous Labs tracks eight competitors: three legacy enterprise analytics incumbents, two vertical startups, two regional consultancies, and one open-source project that shows up in roughly a third of their technical evaluations. None of those eight sell into pure software buyers. Their buyers run plants, recycling yards, and foundries. But the competitive discipline Irina needed is the same discipline a consumer brand, a marketplace, or a services firm needs: know the set, read the moves, decide what to do, and stop reacting to noise.
The fix is not more tracking. The fix is a weekly agentic brief owned by marketing, co-signed by pricing and product, delivered every Monday morning, and instrumented against decisions, not opens.
Part one: define the competitor set with discipline
The first mistake in competitor intelligence is tracking too many or tracking the wrong ones. Both produce the same output: a brief that reads like a newsletter and gets ignored.
Five to eight is the disciplined band. Fewer than five and you miss flanking threats from adjacent categories or open-source alternatives. More than eight and the brief bloats, the analyst drowns, and the signal-to-noise ratio collapses. Ferrous Labs landed on eight because their evaluation patterns genuinely produce eight credible alternatives across three ICPs (enterprise steel, mid-market foundry, metal-recycling cooperative). A consumer brand with one direct competitor and two private-label threats from retailers might land on four. A marketplace fighting two incumbents and three vertical aggregators might land on six.
The set needs structure. For Ferrous Labs, Irina broke the eight into five categories. Direct incumbents, meaning the three legacy enterprise analytics platforms that still win most seven-figure deals in steel. Vertical challengers, meaning two startups building foundry-specific and recycling-specific tools. Adjacent threats, meaning two regional consultancies that bundle software with services and win on relationship. Free and open alternatives, meaning the open-source project that most plant engineers have already installed on a laptop somewhere.
This structure matters because it changes the prompt. When the agent classifies a move, it needs to know whether the move is coming from an incumbent protecting share, a challenger trying to steal it, or an open-source community expanding scope. The same $99 price drop means different things in each category.
Review the set quarterly. The biggest failure mode in competitor tracking is a set frozen 18 months ago that no longer reflects who wins the deal today. Require at least one swap per quarter unless the revenue team documents why the current eight are still the right eight.
Part two: build the agentic stack
The stack has five components. A frontier model (Claude Sonnet, Claude Opus, or GPT-5 at the tier that matches your privacy and cost posture). A crawler that pulls competitor pricing pages, landing pages, blog posts, release notes, and a short list of review sites. A diff utility that tells the agent what changed week over week. A living positioning document that encodes how you want the agent to reason about moves. And a delivery channel, almost always email plus Slack, occasionally a Notion doc pinned in the commercial team's workspace.
Ferrous Labs built version one in two weeks. The crawler was a Firecrawl instance scraping 62 URLs across eight competitors. The diff utility was a Python script comparing this week's scrape to last week's and producing a structured JSON object of added, removed, and changed content. The model was Claude. The positioning document was a 12-page Google Doc that Irina and the product lead rewrote together over a weekend because the version they inherited was two releases out of date. Delivery was an email Irina sent herself Monday at 7am, edited lightly, then forwarded to the commercial leadership group.
Version two, built over the following 90 days, added four things. A classification layer that scores each move as signal or noise with reasoning. A response recommendation for signal-classified moves. A memory of prior classifications so the agent does not rediscover the same observation week after week. And an instrumentation layer that tracks open rate, reply rate, and downstream decisions.
Token cost for Ferrous Labs runs $87 per month. The crawler costs another $40. Total stack cost is under $130 per month and replaces 6 to 10 hours per week of analyst time plus a quarterly deck nobody read.
The build is not the asset. The prompt library is the asset.
Part three: write prompts that produce judgment, not summaries
Most teams building CI agents stop at "summarize what changed." That produces a newsletter. The prompt library needs four prompts that produce judgment.
Prompt A, the scan. Given the diff object, summarize every change competitor by competitor. Output format: competitor name, change type (pricing, positioning, product, people, funding), one-sentence description, source URL. No interpretation yet. Keep it factual and boring.
You are Ferrous Labs' competitive scan agent. Input: a JSON diff object of
competitor content changes over the past seven days. Output: a structured list
of changes, one per row, with competitor, category, description, and source URL.
Do not classify, recommend, or interpret. Report only what changed.
Prompt B, the classification. Given the scan plus the positioning document, classify each change as signal or noise. Signal means a move that could change how we price, position, sell, or build in the next 90 days. Noise means a move that is either immaterial, already anticipated, or strategically irrelevant. Require a reason for every classification.
You are Ferrous Labs' CI analyst. Input: scan output plus the attached
positioning document. For each change, classify as SIGNAL or NOISE and explain
why in one sentence. A pricing move on a tier we do not compete in is noise.
A pricing move on a tier we do compete in is signal. Be conservative. Most
moves are noise.
Prompt C, the implications. For every signal-classified change, write two sentences on what it implies about the competitor's strategy and one sentence on what it implies for us.
Prompt D, the recommendation. For every signal-classified change, recommend one of four responses: monitor (no action, re-evaluate next week), brief the commercial team (internal alignment, no external change), test a response (pricing page copy change, positioning refresh, battlecard update), or escalate to pricing committee (a change that warrants a formal commercial decision). Three out of four signals should be monitor or brief. Test and escalate should be rare and expensive.
Irina's prompt library is now 11 prompts, versioned in Git, co-owned by marketing and product marketing. When positioning shifts, the prompts get updated the same week. That velocity is the reason the brief stays useful.
Part four: close the loop with the commercial team
An unread brief is an expensive diary entry. Close the loop with three instruments.
Open rate. Ferrous Labs set a 70 percent target across a 24-person commercial distribution list (sales leadership, CSM leadership, product, pricing committee, a subset of AEs). Actual open rate sits at 82 percent. They hit the target within six weeks by shortening the brief to under 800 words, moving the most important signal to the top, and naming the author on every send.
Decisions influenced. This is the scoreboard that matters. Ferrous Labs tracks every pricing, positioning, or roadmap decision that cites the brief as an input. In Q3, the brief caught four competitor pricing moves. One produced a response, a starter-tier bundle change rolled out three days after the signal landed, caught because the $299-to-$199 move they missed the previous year was exactly the pattern the agent flagged. Three were classified as noise with documented reasons and did not trigger a response. Zero decisions influenced would mean the brief is producing signal without implications.
Time-to-signal. The lag between a competitor move going live and the brief naming it. Ferrous Labs' baseline was 41 days. Current median is three days, with worst-case seven days for moves that require human verification before the agent flags them. That collapse, from 41 days to 3 days, is the single most important metric in the build, because it is the one the CEO and the pricing committee understand without explanation.
Commercial decisions at Ferrous Labs now move 26 percent faster than the baseline Irina measured in her first month. The brief is not the only reason. But the weekly rhythm, the shared scoreboard, and the classification discipline are the three things every leader in the commercial huddle now cites when asked why pricing decisions no longer take three weeks. The best operators compete on discipline, not instinct, and the brief is how that discipline becomes visible.
Three failure modes to avoid
Crawler-as-newsletter. The most common failure. A team builds the stack, wires up the crawler, and produces a weekly summary of everything that changed. Open rate peaks at 45 percent and declines. The fix is the classification layer. If you do not filter for signal, you are producing noise with extra steps.
Signal-without-implications. The second failure. The brief identifies moves, classifies them as signal, and stops there. The commercial team reads it, nods, and moves on. No decisions influenced. The fix is Prompts C and D, which force the agent to translate signal into implications and implications into a recommended response. If the recommendation is "monitor," say so explicitly. A clear "do nothing" is a decision.
Uninstrumented rollout. The third failure. The brief ships without open-rate tracking, without a decisions-influenced scoreboard, and without a named owner. Six months later, it has become Monday wallpaper. The fix is to instrument before you launch. Publish the three KPIs in the first email. Review them monthly with the commercial leadership group. Cut sections that do not drive decisions. A brief that cannot prove commercial impact will lose the Monday 7am slot within two quarters.
A 30-60-90 sprint
Days one through 30. Agree the competitor set with revenue and product. Rewrite the positioning document. Stand up the crawler against 40 to 80 URLs. Build Prompts A and B. Ship a version-one brief to a three-person pilot group (CMO, CPO, head of sales). Name the owner.
Days 31 through 60. Add Prompts C and D. Expand the distribution list to full commercial leadership. Publish open rate and time-to-signal weekly. Start logging decisions influenced. Cut any section with zero read-through.
Days 61 through 90. Add memory across weeks. Add a quarterly retrospective that reviews the competitor set. Integrate with Slack for same-day signal when a rare high-urgency move needs faster-than-weekly surfacing. Publish the first quarterly scorecard to the board: time-to-signal trend, decisions influenced count, and a short list of moves the brief caught that the team would have missed.
FAQ
What is an AI competitive intelligence brief and why build it weekly? Weekly cadence catches small moves (starter tier drops, landing page refreshes, new hires in CS) that quarterly reviews miss and daily alerts bury. Monday 7am creates a commercial decision artifact for the week.
How is this different from existing CI platforms? Platforms crawl and alert. An agentic brief applies your positioning document, classifies signal vs. noise with reasoning, and recommends a response. You own the prompt library and can tune it in an afternoon.
Do I need engineering resources? A version-one build takes two weeks with one analyst and a senior marketer. Stack cost is under $150 per month for most companies tracking five to eight competitors.
How do I know the brief is working? Three instruments: open rate (target 70 percent), decisions influenced (count), and time-to-signal (lag from move to naming).
What competitors should I track? Five to eight, broken into direct incumbents, vertical challengers, adjacent threats, and free or open alternatives. Review the set quarterly.
How does this handle pricing signal? Pricing is a signal before it is a number. The brief classifies each move, recommends a response or no response, and documents why. Most pricing moves should be classified as noise.
What prevents the brief from becoming ignored? Fixed length under 800 words, fixed structure, named author, and instrumented distribution with a decisions-influenced scoreboard.
How do I roll this out without political friction? Share with pricing, product, and sales leadership pre-launch. Build their asks into the prompt library. Invite one leader to co-sign the first four weeks.
Run the free assessment or book a consultation to apply this framework to your specific situation.
Questions, answered
4 QuestionsWhat is an AI competitive intelligence brief and why does weekly cadence beat quarterly reviews?
An AI competitive intelligence brief is a structured output produced by a frontier model, a crawler, and a diff engine, delivered to commercial leaders on a fixed weekly cadence. The weekly rhythm matters because most competitor moves are small: a starter tier drop, a new landing page, a hire in customer success. Quarterly reviews miss the signal. Daily alerts drown teams in noise. A Monday 7am brief forces a disciplined read every week and creates a decision artifact your pricing, product, and sales leaders can act on before Tuesday standups.
How does an agentic CI brief in Claude or GPT-5 beat existing CI platforms like Crayon or Klue?
Most CI platforms are crawlers with a notification layer. They produce alerts, not judgment. An agentic brief built in Claude or GPT-5 reads a curated competitor set, applies your positioning document, classifies moves as signal or noise with reasoning, and recommends a response. The prompt library is the asset. You own the judgment logic. You can tune it in an afternoon when your positioning shifts, which happens more often than platform vendors admit.
How do you measure whether a weekly competitive intelligence brief is actually working?
Three instruments. Open rate among the commercial distribution list, with a 70 percent target. Decisions influenced, measured as the count of pricing, positioning, or roadmap moves that cite the brief as an input. Time-to-signal, measured as the lag between a competitor move going live and the brief naming it. If open rate drops below 60 percent, the brief is too long or poorly written. If decisions influenced stays at zero, the brief is producing signal without implications.
How should a CI agent classify a competitor pricing move (like a $299 to $199 starter-tier drop)?
Pricing is a signal before it is a number. A competitor dropping a starter tier from $299 to $199 tells you something about their pipeline health, their funding runway, and their ICP panic. The brief should capture the move, classify the likely motive, and recommend a response or explicitly recommend no response. Three out of four pricing moves should be classified as noise with documented reasons.
Replacing ad hoc competitor tracking with an agentic weekly brief built in Claude or GPT-5, instrumented against time-to-signal, decisions influenced, and open rate.
How relevant and useful is this article for you?
About the Author(s)
 Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
References
- Al Ramadan, Dave Peterson, Christopher Lochhead & Kevin Maney. Play Bigger. HarperBusiness, 2016
- April Dunford. Obviously Awesome. Page Two, 2019
- Al Ries & Jack Trout. Positioning. McGraw-Hill, 2001
- Al Ries & Jack Trout. The 22 Immutable Laws of Marketing. HarperBusiness, 1994
- Clayton M. Christensen, Scott Cook & Taddy Hall. Marketing Malpractice: The Cause and the Cure. Harvard Business Review, 2005