
When CAC Payback Crept From 19 to 23 Months: ABM Cells Fix It
Most ABM programs fail because they treat accounts as monolithic and messaging as centrally authored. When a company sells direct to enterprise in three verticals and embeds as an OEM inside nine partner platforms, one account list and one play library cannot serve both motions. The fix is segment-level ABM cells with shared infrastructure, not a single ABM team.
The Operator's Guide to ABM in a Multi-Segment, Multi-Model World
Show me your ABM account list. Now tell me which accounts are direct enterprise targets, which are OEM partner targets, and which are OEM partner end-customer influence targets. If the list is one column of account names with a single fit score, your ABM program is pretending your company is something it is not.
Most multi-model companies run an ABM program that was designed for a monoculture. One list. One message library. One scoring model. One team. It feels efficient. It produces accounts nobody is qualified to sell into and messages nobody wants to read.
TL;DR.
- Multi-segment, multi-model companies cannot run ABM as a single program. Direct enterprise and OEM partner motions have different buyers, different proofs, and different economics. One list flattens all of that into noise.
- The fix is ABM cells. One cell per segment and commercial model combination. Each cell owns its list, its scoring, and its message library. The cell is federated. The data, tooling, and orchestration sit underneath as shared infrastructure.
- Readiness scoring has to be model-specific. A universal fit score treats an insurance underwriter the same as an OEM product team, which is how you end up with a target list full of accounts that fit nobody.
- Measurement happens at the cell level. Program-level CAC and payback hide the cells that work and the cells that burn money to make the average look fine.
- Packaging beats pricing, and cell-specific packaging beats universal packaging. The best operators compete on discipline, not instinct.
The core problem
Meet Harpoon Analytics. 310 people. $112M ARR. A geospatial data and analytics company selling direct to enterprise across three verticals (insurance, logistics, agriculture) with ACVs from $85K to $650K, and embedding as an OEM feature inside 9 partner platforms (fleet management systems, crop insurance underwriting tools, parametric reinsurance engines) on a usage-metered royalty. Direct and OEM revenue split 62/38. The CMO is Aroha.
When Aroha arrived, Harpoon was running a single ABM program. One target list of 430 named accounts. One message library. One fit score. One ABM manager and a shared BDR pool. It looked efficient on paper. In practice, direct enterprise CAC payback had crept from 19 to 23 months over six quarters. OEM-influenced payback was not being measured at all because the attribution model could not tell partner-sourced revenue from direct revenue, so it defaulted to direct.
The diagnostic took three weeks. The 430 accounts included direct insurance prospects, direct logistics prospects, direct agriculture prospects, OEM partner product teams, OEM partner customer success teams, and OEM partner end customers. Six audiences. One list. The fit score had been trained on direct insurance deals and was ranking an OEM fleet-management partner product lead the same way it ranked an insurance underwriter. The message library had 71 tested messages, most written for direct insurance buyers, being recycled into OEM outreach with the vertical references changed.
Pricing is a signal before it is a number. Harpoon's ABM program was signalling that it did not know who it was talking to. Confusion is the enemy of willingness to pay, and a confused ABM program pushes direct ACVs down through discounting and OEM partners into "wait and see" on the co-marketing investment. Six months after Aroha rebuilt the program into cells, direct CAC payback moved from 23 back to 11 months, OEM-influence payback landed at 14 months against a baseline nobody had measured before, and pipeline lifted 28 percent across the four cells that had stood up. The rebuild had four moves.
 Exhibit: ABM cell matrix
Exhibit: ABM cell matrix
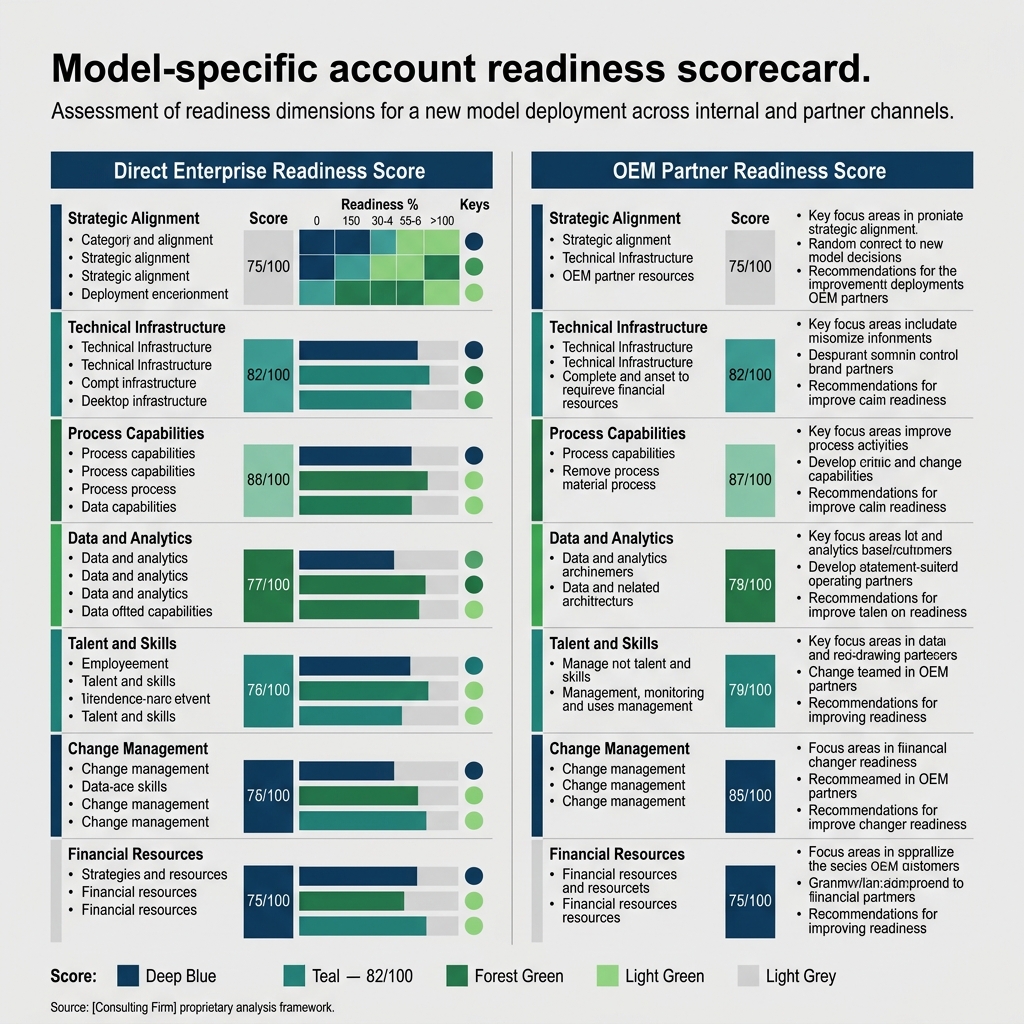 Exhibit: Model-specific account readiness scorecard
Exhibit: Model-specific account readiness scorecard
Part one: name the cells
Aroha's first move was naming the cells. One ABM cell per segment and commercial model combination. Not one per vertical. Not one per motion. The intersection.
Harpoon's cell map came out as nine possible cells (three direct verticals plus three OEM motion patterns across three partner archetypes), and Aroha stood up four in the first six months. Direct insurance. Direct logistics. OEM fleet-management. OEM parametric reinsurance. The rest were scheduled for the second half of the year, sequenced by revenue concentration and readiness to pilot.
Each cell has a named owner. Two to five people. The owner is accountable for the account list, the scoring rubric, the message library, and the quarterly CAC payback number. The BDR pool is federated (each cell has a named BDR or BDR pair, not a round-robin). The orchestration platform is central. The play library is cell-owned.
The cell structure forces prioritization to happen once, at cell-design time, with a named budget and a named owner. The old single-list program forced prioritization to happen every Monday, inside a pipeline meeting, where whichever segment had the loudest revenue leader won the sprint. Four months of that pattern is how you end up with a deck full of insurance case studies and nothing the OEM team can hand to a partner.
Naming the cells is the organizational move that enables every other move. Without it, the scoring model, the message library, and the measurement layer all default back to the segment with the biggest history and the loudest voice. The CMO's job becomes portfolio management across cells, not editorial approval across one list.
One warning. Cells are not a license for fragmentation. The infrastructure underneath has to be genuinely shared or the cells become four parallel mini-ABM-programs. The next move is how you prevent that.
Part two: centralize infrastructure, federate messaging
The infrastructure layer is centralized. The messaging layer is federated. Mixing those up is the single most common failure when operators try to run multi-cell ABM.
Centralized infrastructure covers the data stack (a single CDP or warehouse with segment tags and model tags at the account level), the orchestration platform (one system of record for touches across cells), the measurement layer (one CAC and payback definition applied to every cell), and the brand invariants (the three to five claims the company always makes, tone rules, legal disclosures). If each cell rebuilds its own data stack, you end up with four incompatible definitions of an active account and a board deck nobody can reconcile.
Federated messaging covers the vertical language, the trigger events, the economic buyer hooks, the proof stories, the co-marketing content with partners, and the cadence and channel mix. If central writes the OEM fleet-management library, it will read like the insurance library with the nouns changed. The partner product lead will feel talked at. The campaign will underperform.
Aroha's rule at Harpoon was simple. Brand owns the invariants. Cell owners own the specifics. Central runs a quarterly audit for drift. Cell owners run weekly message reviews. The 71 messages in the old library were pulled apart, reclassified, and rebuilt into four cell-specific libraries with 9 verticalized plays that hold up under pressure.
The test for whether your infrastructure is centralized enough is simple. If you add a fifth cell, how much of the stack do you rebuild? If the answer is more than 10 percent, your infrastructure is not shared, it is co-located. The test for whether your messaging is federated enough is the opposite. If central approves every piece of content before it ships, the cells are subcontractors, not cells. Federate the authorship. Audit the output. Do not invert it.
Part three: score accounts on model-specific readiness
Universal fit scores are the quiet killer of multi-model ABM. A single score trained on the biggest historical segment will always rank that segment's look-alikes highest and under-rank everything else. Harpoon's old score was trained on direct insurance deals. The 430-account list reflected that. The OEM partner product leads who should have been the top of the OEM fleet-management cell were buried in the middle of the list because the score did not know what an OEM partner product lead looked like.
Each cell needs its own score. Same general shape, different inputs.
For a direct enterprise cell, readiness weights trigger events that matter to that vertical's economic buyer, intent signals on the specific use case the cell sells, firmographics that match the ACV band, and recent changes in the buying committee. Harpoon's direct insurance cell weights new VP of underwriting, recent reinsurance treaty renewals, M&A in the past six months, and observed intent on parametric and flood use cases. The direct logistics cell weights different triggers (new head of fleet, fuel cost volatility, regulatory changes on emissions reporting).
For an OEM cell, readiness is a three-audience problem. You are scoring the partner's product team (roadmap alignment, recent platform launches, technical fit with your data), the partner's customer success organization (active customer count, expansion motion, openness to co-marketing), and the partner's end customers (overlap with your direct footprint, propensity to ask for your data inside the partner's product). One score cannot cover all three. Harpoon's OEM cells each run three sub-scores and a rollup, which sounds complicated and is, and is still simpler than pretending one number covers it.
Harpoon ended up with 47 OEM "tier 1" accounts across the nine partners, identified by the rollup scores. Those 47 get co-marketing investment, named account plans, and quarterly joint business reviews. The rest of the partner universe gets a lighter touch.
Packaging beats pricing, and cell-specific packaging starts with knowing who you are packaging for. The score is how you know.
Part four: measure cell-level CAC and payback
Program-level CAC is where dead cells go to hide. If the blended number looks fine, nobody asks why the OEM reinsurance cell burned budget for two quarters with no partner-sourced pipeline. The average covers for the failure. The failure continues.
Aroha's measurement rule at Harpoon is that every cell reports CAC and payback quarterly against a cell-specific target. Direct insurance targets 11 months on a mix of $85K to $320K ACVs. Direct logistics targets 13 months on slightly lower ACVs. OEM fleet-management targets 14 months on influenced partner-sourced revenue. OEM parametric reinsurance targets 18 months, reflecting the longer cycle. Each target was set against a baseline from the last four quarters of historical data, with a planned improvement trajectory for the coming year.
The measurement rule has two consequences. First, the CMO knows inside one quarter which cell is working and which cell is not. The old program gave Aroha a blended number and a quarterly argument about whether the movement was signal or noise. Cell-level numbers give her four separate signals and four separate conversations. Second, the cells start behaving like portfolio assets. The OEM parametric reinsurance cell knows it has a longer payback window and stops apologizing for its quarterly conversion numbers. The direct insurance cell knows it is inside its band and starts investing in expansion plays rather than defending its top-of-funnel.
Cell-level measurement does one more thing. It forces the attribution conversation to happen at the cell boundary, not the program boundary. Harpoon's old attribution model could not distinguish OEM-influenced revenue from direct revenue because the account-level tags were inconsistent. The cell rebuild forced the data team to put clean model tags on every account and every deal, which took six weeks and produced the first OEM-influence CAC number the company had ever reported. 14 months against a baseline of nothing. Next year it has a trajectory.
The best operators compete on discipline, not instinct. Cell-level measurement is that discipline.
Where this breaks
Three failure modes. Each one is common. Each one costs real money.
Failure one: one-list ABM. The single target list survives the reorg because it is easy to maintain and easy to report on. The list hides the segment mismatch underneath. Direct and OEM accounts sit side by side with no model tag. The BDR team works it top-down, calling whichever account has the highest score, which is almost always a direct enterprise account because that is where the score was trained. The OEM motion starves. Fix: refuse to maintain a single list. Every account gets a cell tag before it enters the system. If it does not have a cell, it does not enter.
Failure two: centrally authored messaging. Central writes the message library for all cells because it preserves brand voice and moves fast. The OEM fleet-management cell sends outreach written by someone who has never sat inside a fleet-management product review. The messages are grammatically fine and strategically vacant. Partners stop responding. Central blames the cell for poor execution. The cell blames central for out-of-touch copy. Both are right. Fix: federate the authorship. Central owns the invariants. Cells own the specifics. Audit the output, do not pre-approve it.
Failure three: partner channel as an afterthought. The OEM cells get built last, resourced thinnest, and measured against direct-style KPIs. The partner-influence number never gets clean. Leadership concludes the partner motion is unprofitable and cuts budget. The partners notice. The sell-through motion decays. Two years later the 38 percent of revenue from OEM shrinks and the company rediscovers the channel the hard way. Fix: resource the OEM cells from day one with dedicated headcount, partner-specific plays, and a payback target calibrated to the partner motion. If you cannot resource the OEM cell, do not claim to run an ABM program against it.
The 30-60-90 sprint to install cell-based ABM
Days 1 to 30. Cell design and scoring rubric. Map the segments and commercial models. Choose the four cells you will stand up first based on revenue concentration and readiness to pilot. Name the cell owners. Build the cell-specific scoring rubrics in draft. Inventory the existing message library and classify every message by cell. Publish the cell map to the leadership team. Do not start running plays yet.
Days 31 to 60. Pilot plays in two cells. Pick the two highest-confidence cells (usually the two direct verticals you already know best). Run one cell-specific play per cell. Use cell-specific messaging. Measure pipeline generated and opportunity quality. Do not try to run plays across all four cells in month two. The discipline of constraining to two cells builds the operating habit. Use the time to harden the shared infrastructure (data tags, CRM fields, orchestration platform) for the remaining two cells.
Days 61 to 90. Pilot plays in the remaining cells and run the first cell-level CAC payback review. Stand up the two OEM cells with their three-audience scoring and their partner-co-authored messaging. Run one play per cell. Run the first quarterly CAC payback review across all four cells. Publish the numbers to leadership. Resist the urge to average across cells. The point of the review is that each cell has its own number and its own conversation. Plan the next quarter cell by cell, not as a program.
FAQ
Why do most ABM programs fail inside multi-model companies? They were built for a single motion. One list, one message, one scoring model. When the team tries to stretch that across direct enterprise and OEM partner motions, the list becomes noise and the scoring model over-credits accounts that look like the biggest past deal.
What is an ABM cell? A small operating unit (two to five people) owning ABM for one segment inside one commercial model. Each cell owns its list, scoring rubric, message library, and CAC payback target. Shared infrastructure sits underneath.
Why not one team with segment specialists? Because the prioritization decision has to happen once, at cell-design time, with a named owner and a named budget. A shared backlog re-litigates priorities every Monday and the loudest revenue leader wins every quarter.
How is an OEM cell different from a direct cell? An OEM cell markets to the partner's product team, their customer success team, and their end customers at the same time. Three audiences, not one. Measurement is against influenced partner-sourced revenue, not direct pipeline.
What is model-specific readiness scoring? A readiness score calibrated to the motion. Direct weights trigger events and buying committee change. OEM weights partner roadmap alignment, customer overlap, and sell-through economics. One score cannot cover both.
How do we federate messaging without brand drift? Central owns the invariants (three to five claims, tone rules, legal). Cells own the specifics (vertical language, proof stories, co-marketing with partners). CMO audits quarterly. Do not pre-approve, do audit.
What does a cell-level CAC payback target look like? Direct cells target payback windows based on ACV band (often 9 to 18 months). OEM cells target longer windows against influenced partner-sourced revenue, usually 14 to 20 months.
How long does it take to stand up a cell structure? Six months for four cells if the data is clean and the CMO has headcount authority. Standing up six or more cells at once usually collapses back to a single list inside a quarter.
Run the free assessment or book a consultation to apply this framework to your specific situation.
Questions, answered
8 QuestionsWhy do most ABM programs fail inside multi-model B2B companies (direct plus OEM)?
They were built for a single motion. One list. One message. One scoring model. When the same team then tries to run ABM across a direct enterprise motion and an OEM partner motion, the list becomes noise, the message becomes bland, and the scoring model over-credits accounts that look like the biggest past deal. The failure is structural, not tactical. You cannot fix it with better copy or a new intent signal. You have to break the program into cells, one per segment and model combination, and give each cell its own scoring and its own message library.
What is an ABM cell and how is it staffed?
An ABM cell is a small operating unit (two to five people) owning ABM for one segment inside one commercial model. A cell covers a specific vertical sold through a specific motion. Direct insurance, direct logistics, direct agriculture, OEM fleet-management platforms, and OEM parametric reinsurance engines are each candidates for their own cell. Each cell owns its account list, its scoring rubric, its message library, and its CAC payback target. Shared infrastructure (data, tooling, orchestration) sits underneath all cells. The cell is federated. The plumbing is centralized.
Why not run one big ABM team with segment specialists instead of cells?
Because the scoring logic and message calibration inside a specialist's head cannot survive a shared backlog. When one team has to prioritize work across five segments, the segment with the loudest revenue leader wins the quarter. The other four get brochureware. A cell structure forces the prioritization decision to happen once, at the cell level, with a named owner and a named budget. You stop re-litigating priorities every Monday.
How is an OEM partner ABM cell different from a direct enterprise ABM cell?
An OEM cell is marketing to a partner's product team, to their end customers, and often to their customer success organization at the same time. The economic buyer inside an OEM partner is rarely the person you met during the partnership deal. The cell has to map three audiences, build plays that support the partner's sell-through instead of competing with it, and measure influence on partner-sourced revenue, not direct pipeline. The tactics rhyme with direct ABM. The economics do not.
What is model-specific account readiness scoring inside an ABM cell?
A readiness score calibrated to the commercial motion the account sits in. For a direct enterprise account, readiness might weight trigger events like a new VP of underwriting, a recent M&A, and observed intent on a specific vertical use case. For an OEM target, readiness weights the partner's product roadmap alignment, their customer overlap with your direct footprint, and the strategic fit of their sell-through economics. A universal fit score flattens those differences and produces an account list that fits nobody well. Each model needs its own score.
How do you federate ABM messaging across cells without creating brand drift?
You centralize the invariants and federate the specifics. Invariants are the three to five claims the company always makes, the tone rules, and the proof points that are allowed in any piece of content. Specifics are the vertical language, the trigger events, the economic buyer hooks, and the proof stories that belong inside one cell and nowhere else. Central brand owns the invariants. Cell owners own the specifics. The CMO spot-audits once a quarter. Drift is manageable. Blandness is not.
What does a cell-level CAC payback target look like across direct and OEM ABM?
Direct enterprise cells typically set a CAC payback target in months based on their ACV band. An $85K ACV direct cell might target 14 to 18 months. A $650K ACV direct cell might target 9 to 12. OEM cells measure payback on influenced partner-sourced revenue rather than direct closed-won, and typically carry a longer payback window because the revenue compounds through partner sell-through. Reporting cell-level payback quarterly is the single most useful discipline a CMO can install. Program-level blended CAC hides the cells that are subsidizing the cells that do not work.
How long does it take to stand up an ABM cell structure across four segments?
Six months is realistic for four cells if you already have the data, a CRM that supports segment tagging, and a CMO with the authority to move headcount. The first two months are cell design, scoring rubrics, and message-library inventory. Months three and four are pilot plays inside two cells. Months five and six are pilot plays inside the remaining cells plus the first quarterly CAC payback review. Companies that try to stand up six or more cells at once usually collapse back to a single list within a quarter. Start with four.
Most ABM programs fail because they treat accounts as monolithic and messaging as centrally authored. When a company sells direct to enterprise in three verticals and embeds as an OEM inside nine partner platforms, one account list and one play library cannot serve both motions. The fix is segment-level ABM cells with shared infrastructure, not a single ABM team.
How relevant and useful is this article for you?
About the Author(s)
 Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
References
- Geoffrey Moore. Crossing the Chasm. HarperBusiness, 2014
- Aaron Ross & Marylou Tyler. Predictable Revenue. PebbleStorm, 2011
- Matthew Dixon & Brent Adamson. The Challenger Sale. Portfolio/Penguin, 2011
- Philip Kotler, Neil Rackham & Suj Krishnaswamy. Ending the War Between Sales and Marketing. Harvard Business Review, 2006
- OpenView Partners. SaaS Benchmarks Report. OpenView Partners, 2023