
Time-to-First-Reorder: 34 Days to 11 in One Quarter
Instrument the job-completion path before adding features. Retire signals that do not drive decisions. Tie every roadmap item to a telemetry hypothesis committed before build.
The Operator's Guide to Telemetry Before Features
Most product teams build first and measure later. The measuring never quite catches up. The roadmap keeps moving. The dashboards keep multiplying. Nobody can point to the last decision a signal actually changed.
This guide is for operators who have decided to run product the other way around.
TL;DR
- Instrument the job-completion path before you add to the product. Features without signals are guesses you cannot audit.
- Measure the job, not the page. In marketplace and hardware models, the meaningful events happen off-screen.
- Retire signals that do not drive decisions. A dashboard nobody acts on is a tax, not an asset.
- Tie every roadmap item to a telemetry hypothesis committed before build. If you cannot state the signal that will move, you are not ready to ship.
- Treat telemetry as the operating system of the product, not a retrofit after launch.
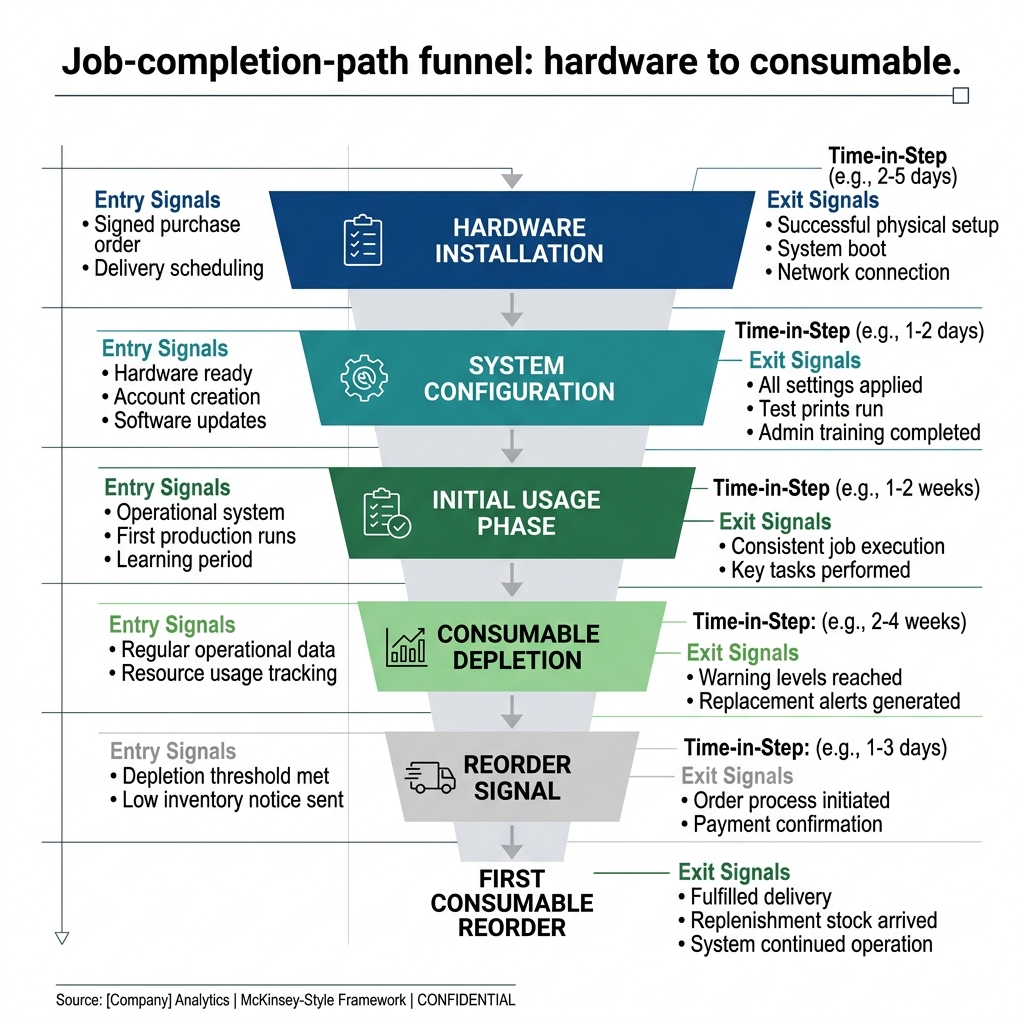 Exhibit: Job-completion-path funnel
Exhibit: Job-completion-path funnel
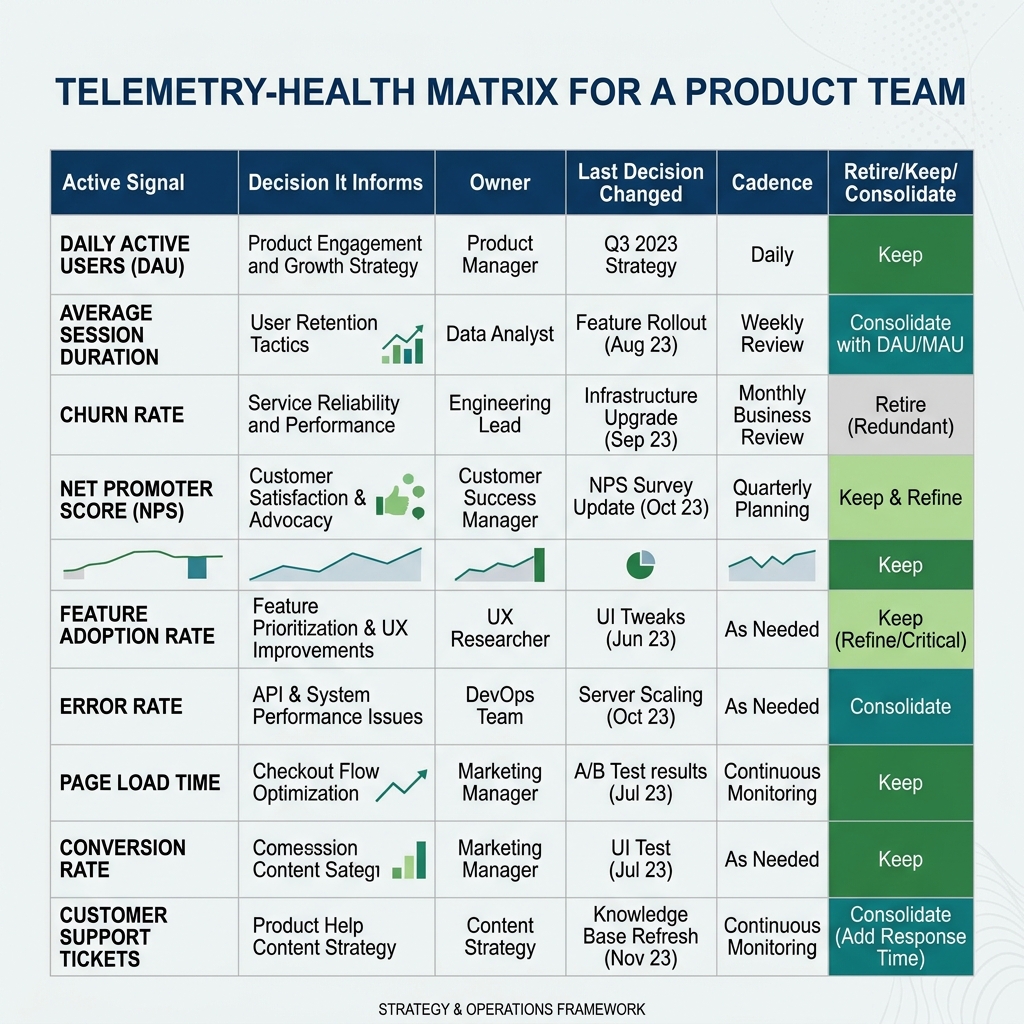 Exhibit: Telemetry-health matrix
Exhibit: Telemetry-health matrix
The core problem
Bristle & Bowline sells combi ovens, blast chillers, and sous-vide circulators into 1,200 independent restaurant groups across North America. They also sell the recurring consumables those machines need to keep running: probe calibration kits, gasket replacements, cleaning fluids. Hardware runs $4K to $45K per unit and moves slowly. Consumables run $35 to $220 per order and move constantly. The split across $94M in GMV is 34% hardware and 66% consumables. The product is the quoting, installation-scheduling, and replenishment platform that ties all of it together.
Yusra runs product. Her team of 75 had shipped 11 hardware category pages, 480 consumable SKU pages, a quoting flow, an installation calendar, and a replenishment prompt. Every quarter, the roadmap filled with requests from the ten loudest accounts. Every quarter, the team shipped. Every quarter, the business metrics moved by rounding error.
When Yusra audited what her telemetry actually told her, she found the problem. The team had built sixty-three dashboards. Nobody could name a decision any of them had changed in the last two quarters. Thirty-nine percent of the features on the roadmap had no supporting signal at all. They came from account managers relaying customer quotes. The team had been building in the dark and calling the dashboards a flashlight.
The fix was not more dashboards. The fix was to rebuild the product around the jobs customers were actually trying to complete, and to instrument those jobs before touching anything else.
Part one: Name the job-completion path before you instrument anything
Telemetry without a named job is noise with a chart on top. Before you capture a single event, you need the ordered sequence of steps a customer takes from intent to outcome. That sequence is the unit of analysis. Features sit inside it. Screens sit inside it. The path itself is the thing.
For Bristle & Bowline, Yusra named three paths. First: quote issued to purchase order accepted. Second: hardware delivered to first successful installation. Third: installation complete to first consumable reorder. Every other surface in the product was a supporting actor. The three paths were the show.
Each step inside each path needed three properties. An entry signal. An exit signal. A timeout. If a step had no entry signal you did not know when it started. If it had no exit signal you did not know when it ended. If it had no timeout you could not tell the difference between slow and stuck. Most teams instrument entries and forget exits. Most teams forget timeouts entirely.
Once the three paths were named, the team ran a ninety-minute session per path with the account managers, the field techs, and two customers on the phone. They traced the path step by step. Where did people get confused. Where did they ask for help. Where did they give up. Where did the system assume something the customer did not know. That session produced a drop-off map for each path before a single new event was wired.
The payoff: the team now had a shared vocabulary. When somebody proposed a feature, the first question was which step on which path does this serve. If the answer was unclear, the feature went to the parking lot. If the answer was clear, the next question was what signal will tell us it worked. Pricing maturity is measured by what you stop doing, and the same rule applies to product. The discipline starts with knowing what you are trying to measure.
Part two: Instrument the job, not the page
Page views are cheap and lying. A marketplace customer can view the replenishment page three times and never reorder. A customer can skip the page entirely and reorder by email. The page is a surface. The job is the reorder.
Instrumenting the job means capturing events that correspond to real-world outcomes, not to clicks. For Bristle & Bowline, the events that mattered were these. Liquidity: how many consumable SKUs had at least one reorder in the last thirty days across all 1,200 accounts. Attach rate: what percentage of hardware installs produced a consumable reorder inside sixty days. Time-to-replenish: median days from install to first consumable order. Field-tech completion rate: percentage of installs where the tech marked the job closed inside one visit.
None of these events lived naturally on a page. Liquidity lived in the order table. Attach rate required joining the hardware install table to the consumable order table. Time-to-replenish required a timer that started at install and stopped at first reorder. Field-tech completion required the tech app to send a close event that the web app had never needed.
The team wired all of it. Then they connected each signal to a specific decision. Liquidity informed which consumables to promote and which to deprecate from the 480-SKU catalog. Attach rate informed whether the replenishment prompt was working. Time-to-replenish informed whether the install-to-reorder handoff was broken. Field-tech completion informed whether the scheduling system was setting techs up for success.
Inside one quarter, attach rate moved from 58% to 81%. Time-to-first-replenishment dropped from 34 days to 11. NPS rose 14 points for operators and 8 points for field techs. The features that produced those numbers were small. The instrumentation was not. The instrumentation came first.
Marketplace operators have a specific advantage here that SaaS teams do not. When your revenue depends on physical events across 1,200 accounts and 11 hardware categories, you cannot fake progress with session counts. Either the combi oven got installed or it did not. Either the gasket got reordered or it did not. The events are legible, but only if you wire them. Most teams wire the vanity events first because they are the easiest to ship. The discipline is to wire the revenue events first, even when they are harder, even when they require a new table and a new handoff from the field-tech app to the web app. A signal that costs two weeks to build and drives a decision every week is worth more than five dashboards that cost a day each and drive nothing.
Part three: Run a data-you-do not-use retire review on the telemetry itself
Telemetry rots. Signals that once drove decisions stop driving them. Dashboards get built for a specific question, get answered, and then stay on the wall. Every signal you keep is overhead. Every dashboard you keep is a cognitive tax on every person who scans the wall looking for the one that matters.
The retire review runs quarterly. Yusra sets aside a two-hour block. Every dashboard gets a one-line answer to one question: what decision did this change in the last ninety days. No answer, no dashboard. A dashboard that exists because somebody built it three quarters ago and nobody has the heart to delete it is not an asset. It is debt.
The first review at Bristle & Bowline killed 22 dashboards and consolidated 14 more into four. The team also retired 18 roadmap items that no longer had a live telemetry hypothesis. The roadmap shrank. The team got faster. Nobody outside the team noticed anything had been deleted, which is how you know it was safe to delete.
The review also catches signals that were never tied to a decision in the first place. These are the worst kind because they masquerade as rigor. A metric with a dashboard and a weekly review that nobody has ever acted on is theater. Retire it. The discipline of subtracting signals is the same muscle as the discipline of subtracting features. Confusion is the enemy of willingness to pay, internally and externally.
There is a second cut the review should make. Signals that exist for a single stakeholder who never shares what they learned. A finance dashboard nobody in product has seen. A product dashboard nobody in finance has seen. If a signal is not cross-functional, it is either mislabeled or misplaced. Move it to the team that acts on it, or retire it. The wall of the operating room should have the signals that any operator needs to make the next call, and nothing else. Yusra kept the rule simple. If you cannot explain the signal to a new hire in thirty seconds, it does not belong on the wall.
Part four: Tie every roadmap item to a telemetry hypothesis committed before build
Every roadmap item gets one sentence before it gets engineering time. The sentence has four parts. If we ship X, signal Y will move by Z within W weeks. No sentence, no build. If the sentence is vague, rewrite it until it is specific. If nobody on the team will sign the sentence, the item is not ready.
At Bristle & Bowline, the sentence for the revised replenishment prompt was this. If we ship a calibration-kit reorder reminder tied to the install date, attach rate will move from 58% to at least 70% inside eight weeks. The team signed it. The team shipped. Eight weeks later, attach rate sat at 76%. The hypothesis was right, but slightly under. The team documented the gap and moved on.
The sentence for a proposed quote-revision feature went the other way. The team could not name a signal that would move. The item went to the parking lot. An account had asked for it loudly. The account would survive without it. The team used the capacity on a field-tech dispatch improvement that had a live hypothesis and a measurable step on the install path.
When the hypothesis is wrong, you learn something. When the hypothesis was never written, you learn nothing. The write-down matters more than the outcome. A team that ships without hypotheses will ship the same mistake twice.
This discipline also prevented a $7.1M inventory write-down. The team had been planning to stock three new consumable categories based on loud-account requests. The telemetry hypothesis exercise forced the question of which signal would justify the stock. No signal existed. The team ran a ninety-day sensing test with pre-orders instead. Demand was 40% of what the loud accounts had suggested. The stock never got ordered.
The hypothesis sentence has a second benefit that compounds over time. It creates a written record of what the team believed and when. Six months later, you can walk the record. Which hypotheses were right. Which were wrong. Which were vague enough to be unfalsifiable. The teams that get good at this do not get good by building better features. They get good by writing better hypotheses. A team that writes 40 hypotheses a year and holds itself to the signal on each one will outrun a team that ships twice as many features without a written prediction. The best operators compete on discipline, not instinct. The hypothesis log is the discipline made visible.
Three failure modes
Dashboard-as-decor. The team builds a wall of charts because the wall looks serious. Nobody acts on any of them. The wall is a costume. Kill dashboards that do not change decisions, even if they look impressive in the board deck.
Survivorship bias on the loudest accounts. Ten of 1,200 accounts send 80% of the feature requests. The team builds for them and calls it customer-centric. The other 1,190 accounts churn quietly because the product never serves their path. Telemetry forces you to see the silent majority.
Telemetry-as-retrofit. The team ships the feature, then asks engineering to wire events afterward. The events land late, partial, or wrong. The feature gets defended by the people who built it because there is no clean signal to argue against them. Instrument first. Ship second. The order is non-negotiable.
Thirty, sixty, ninety
Days one to thirty. Name the top three job-completion paths. Map the steps. Identify entry, exit, and timeout signals for each step. Run the retire review on existing dashboards. Delete ruthlessly.
Days thirty-one to sixty. Wire the missing instrumentation for the top path. Stand up one dashboard per path with one owner and one decision cadence. Cap total dashboards at the number of paths plus two. Write telemetry hypotheses for every active roadmap item. Park the items that cannot produce a hypothesis.
Days sixty-one to ninety. Ship the first feature with a signed hypothesis. Hold the hypothesis against the signal at the eight-week mark. Document the gap. Run the retire review again. Extend the instrumentation to the second and third paths.
Frequently asked questions
What does "telemetry before features" actually mean in practice?
It means you instrument the job a customer is trying to complete before you add anything new to the product that supports that job. You define the steps, capture events at each step, and watch where the path breaks. Only then do you decide what to build. The discipline forces the question "what will this signal tell us" before the question "what will this feature do." It kills vanity roadmap items and protects engineering capacity for the few bets that move a measurable step forward.
Why is this framed for marketplaces and hardware, not B2B SaaS?
SaaS teams have mature toolchains for in-app events. Marketplace and hardware operators do not. The meaningful signals live in physical events: a unit installed, a probe calibrated, a consumable reordered, a field tech dispatched. These events arrive late, arrive partial, or never arrive at all. The discipline to instrument them is harder and the payoff is larger. A SaaS team loses a click. A marketplace loses a reorder window. The shape of the problem is different.
How do you know a signal is worth keeping?
Tie it to a decision. If nobody has made a different choice in the last ninety days because of that signal, retire it. Dashboards accumulate the way closets accumulate. The question is not "is this metric interesting" but "does this metric change what we do next week." Yusra at Bristle & Bowline runs a quarterly signal retire review. Eleven dashboards were killed in the last cycle. Nobody noticed. That is the point.
What is a job-completion path?
The ordered sequence of steps a user takes from intent to outcome, measured end-to-end. For Bristle & Bowline, one path runs from hardware install to first consumable reorder. Another runs from quote issued to purchase order accepted. You name the path, you name the steps, you name the drop-off points. Then you instrument each step. The path is the unit of analysis, not the screen or the feature. Screens get redesigned. Paths persist.
How do you avoid dashboard overload once you start instrumenting?
Set a cap. One dashboard per job-completion path. One owner per dashboard. One decision cadence per dashboard. If a signal does not fit an existing dashboard, you do not add a new dashboard. You ask whether the signal belongs on an existing one or whether it should not exist. Confusion is the enemy of willingness to pay. The same logic applies internally. Too many dashboards means no decisions get made.
When do you commit to a telemetry hypothesis?
Before engineering writes code. Every roadmap item gets a one-line hypothesis of the form "if we ship X, signal Y moves by Z within W weeks." If you cannot write that sentence, the item is not ready. After build, you hold the hypothesis against the signal. If the signal did not move, you do not claim the feature worked. You either remove it, fix it, or admit you were wrong. The discipline compounds.
What if the telemetry reveals a feature should be killed?
Kill it. The cost of carrying a feature nobody uses is never zero. It shows up in support tickets, onboarding length, code surface area, and the cognitive tax on every subsequent decision. Bristle & Bowline retired eighteen roadmap items after their first telemetry audit. None of the accounts flagged the removals. The best operators compete on discipline, not instinct. Discipline means subtracting when the data says subtract, even when a loud account asked for the thing.
How long before this starts paying off?
First signals inside thirty days if you scope a single job-completion path. First roadmap decisions inside sixty days. Measurable movement on the business metric inside ninety days. Bristle & Bowline cut time-to-first-replenishment from thirty-four days to eleven inside one quarter. The trap is trying to instrument everything at once. Pick the path that sits closest to revenue, ship the instrumentation, retire the noise around it, and extend from there.
Run the free assessment or book a consultation to apply this framework to your specific situation.
Questions, answered
8 QuestionsWhat does 'telemetry before features' actually mean for a product team?
It means you instrument the job a customer is trying to complete before you add anything new to the product that supports that job. You define the steps, capture events at each step, and watch where the path breaks. Only then do you decide what to build. The discipline forces the question 'what will this signal tell us?' before the question 'what will this feature do?' It kills vanity roadmap items and protects engineering capacity for the few bets that move a measurable step forward.
Why is telemetry-first discipline framed for marketplaces and hardware, not pure SaaS?
SaaS teams have mature toolchains for in-app events. Marketplace and hardware operators do not. The meaningful signals live in physical events: a unit installed, a probe calibrated, a consumable reordered, a field tech dispatched. These events arrive late, arrive partial, or never arrive at all. The discipline to instrument them is harder and the payoff is larger. A SaaS team loses a click. A marketplace loses a reorder window. The shape of the problem is different.
How do you know a product signal or dashboard is worth keeping?
Tie it to a decision. If nobody has made a different choice in the last ninety days because of that signal, retire it. Dashboards accumulate the way closets accumulate. The question is not 'is this metric interesting' but 'does this metric change what we do next week.' Yusra at Bristle & Bowline runs a quarterly signal retire review. Eleven dashboards were killed in the last cycle. Nobody noticed. That is the point.
What is a job-completion path and why is it the right unit of analysis?
The ordered sequence of steps a user takes from intent to outcome, measured end-to-end. For Bristle & Bowline, one path runs from hardware install to first consumable reorder. Another runs from quote issued to purchase order accepted. You name the path, you name the steps, you name the drop-off points. Then you instrument each step. The path is the unit of analysis, not the screen or the feature. Screens get redesigned. Paths persist.
How do you avoid product dashboard overload once instrumentation starts?
Set a cap. One dashboard per job-completion path. One owner per dashboard. One decision cadence per dashboard. If a signal does not fit an existing dashboard, you do not add a new dashboard. You ask whether the signal belongs on an existing one or whether it should not exist. Confusion is the enemy of willingness to pay. The same logic applies internally. Too many dashboards means no decisions get made.
When should a product team commit to a telemetry hypothesis on a roadmap item?
Before engineering writes code. Every roadmap item gets a one-line hypothesis of the form 'if we ship X, signal Y moves by Z within W weeks.' If you cannot write that sentence, the item is not ready. After build, you hold the hypothesis against the signal. If the signal did not move, you do not claim the feature worked. You either remove it, fix it, or admit you were wrong. The discipline compounds.
What do you do when telemetry reveals a feature should be killed?
Kill it. The cost of carrying a feature nobody uses is never zero. It shows up in support tickets, onboarding length, code surface area, and the cognitive tax on every subsequent decision. Bristle & Bowline retired eighteen roadmap items after their first telemetry audit. None of the accounts flagged the removals. The best operators compete on discipline, not instinct. Discipline means subtracting when the data says subtract, even when a loud account asked for the thing.
How long before telemetry-before-features discipline pays off in business metrics?
First signals inside thirty days if you scope a single job-completion path. First roadmap decisions inside sixty days. Measurable movement on the business metric inside ninety days. Bristle & Bowline cut time-to-first-replenishment from thirty-four days to eleven inside one quarter. The trap is trying to instrument everything at once. Pick the path that sits closest to revenue, ship the instrumentation, retire the noise around it, and extend from there.
Instrument the job-completion path before adding features. Retire signals that do not drive decisions. Tie every roadmap item to a telemetry hypothesis committed before build.
How relevant and useful is this article for you?
About the Author(s)
 Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
Emily Ellis is the Founder of FintastIQ. Emily has 20 years of experience leading pricing, value creation, and commercial transformation initiatives for PE portfolio companies and high-growth businesses. She has previous experience as a leader at McKinsey and BCG and is the Founder of FintastIQ and the Growth Operating System.
References
- Eric Ries. The Lean Startup. Crown Business, 2011
- Teresa Torres. Continuous Discovery Habits. Product Talk, 2021
- Marty Cagan. Inspired. Wiley, 2018
- Sean Ellis & Morgan Brown. Hacking Growth. Crown Business, 2017
- Alistair Croll & Benjamin Yoskovitz. Lean Analytics. O'Reilly Media, 2013